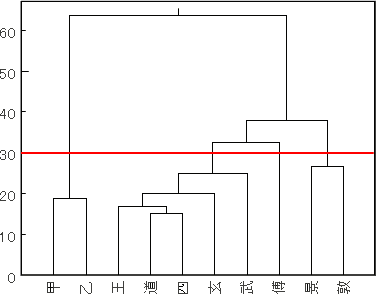
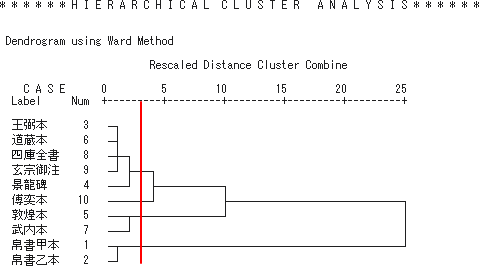
『老子』諸本 NGSM クラスター分析結果
『老子』諸本 NGSM クラスター分析結果凡例
この表は『老子』NGSM データをクラスター分析にかけたものである。
【図1】のデンドログラム(樹形図)は Microsoft Excel 2000 + Cluster2400B.xls(早狩進氏作の Excel用クラスター分析アドイン)によって作成したものである。機能的な制約から分散値上位 1.50 以上(サンプル数: 507x10)のデータを抽出してクラスター分析(ウォード法 → 標準化ユークリッド平方距離)にかけている。図の朱線をボーダーラインとして設定すると、概ね[帛書本系統](馬王堆甲・乙本)、[玄宗御注本系統](王弼本・道藏河上公本・四部叢刊本・玄宗御注本・武内義雄本)、[傅奕本]、[唐鈔本系統](景龍碑・敦煌本)の4つのクラスター(群)に分けることができる。(※清儒・嚴可均は、王弼本・河上公本をはじめとする伝存している今本の多くが、唐の開元年間にそれまでの諸本を整理・校定したとされる玄宗御注本の影響を受け、御注本寄りに本文の字句が改められてしまっていると指摘している。[玄宗御注本系統]のクラスターはその辺りが反映されているものと思われる。)
【図2】のデンドログラム(樹形図)は SPSS を利用してクラスター分析(ウォード法 → ユークリッド平方距離)をかけた結果である。こちらは 1gram ~ 6gram の全データを一括して処理している。やはり朱線部をボーダーラインとして4つのクラスターに分けると、こちらでは景龍碑が[玄宗御注本系統]の諸本に近づき、武内義雄本が敦煌本と同一のクラスターを構成している(※これは恐らく武内本が敦煌本を参校資料に利用しているためであろう)。
表中の略号はそれぞれ、[甲]= 馬王堆帛書甲本、[乙]= 馬王堆帛書乙本、[王]= 江戸明和王弼本(宇佐美本)、[景]= 景龍易州龍興観碑、[敦]= 敦煌唐鈔本( S6453 + P2589 )、[道]= 正統道藏河上公章句本、[武]= 武内義雄校定本(拠本邦伝存古鈔本)、[四]= 文淵閣四庫全書本、[玄]= 正統道藏開元玄宗御注本、[傅]= 正統道藏道徳經古本篇 を示している。これらの諸本に関する詳細は、拙稿「『老子』傅奕本来源考」(『漢字文献情報処理研究』4、2003)を参照されたい。